평균, 분산, 표준편차
⸻
- 평균(Mean)
“평균은 데이터의 중심값”
쉽게 말하면 모든 값을 더한 후 개수로 나눈 값이야.
🔹 예시:
네 친구들과 시험 점수를 비교해보자.
• 너: 80점
• 친구 A: 90점
• 친구 B: 70점
• 친구 C: 60점
• 친구 D: 100점
이 다섯 명의 평균을 구하려면,

즉, 평균 점수는 80점!
평균을 알면 “대략 이 정도 점수가 보통이구나”라고 생각할 수 있어.
⸻
- 분산(Variance)
“데이터가 평균에서 얼마나 떨어져 있는지 측정하는 값”
평균이 80점이라고 했을 때, 친구들의 점수는 80점 근처에 몰려있을 수도 있고,
아주 널리 퍼져 있을 수도 있어.
분산이 크면 데이터가 흩어져 있고, 작으면 데이터가 평균 근처에 모여 있어.
🔹 예시 (다시 시험 점수 사용)
1. 먼저 각 점수에서 평균(80점)을 뺀 값을 구해보자.
(80 - 80) = 0, (90 - 80) = 10, (70 - 80) = -10, (60 - 80) = -20, (100 - 80) = 20
2. 각각 제곱을 해서 항상 양수로 만든다.
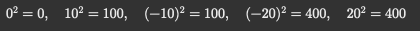
3. 이 값들의 평균을 구하면 분산이다!

👉 이 데이터의 분산은 200!
분산이 크다는 것은 점수들이 평균(80) 근처에 모여 있지 않고, 많이 퍼져 있다는 뜻이야.
⸻
- 표준편차(Standard Deviation)
“분산의 제곱근을 씌운 값”
왜냐면 분산은 제곱을 했기 때문에 원래 단위(점수)보다 커져 있어. 그래서 다시 원래 단위로 돌려놓기 위해 제곱근을 씌운 것이 표준편차야.
🔹 예시 (아까 구한 분산 사용)

👉 표준편차는 약 14.14점!
즉, 친구들의 점수는 평균(80점)에서 약 14.14점 정도 차이가 난다고 볼 수 있어.
⸻
한눈에 정리하면?

⸻
마무리: 현실에서 어떻게 쓰일까?
✔ 학교 성적: 반 평균을 보고 “내 점수가 높은지 낮은지” 판단할 수 있어.
✔ 스포츠: 평균 득점과 표준편차를 보면 선수의 성적이 일정한지, 기복이 심한지 알 수 있어.
✔ 경제: 주식의 표준편차가 크면 위험한 주식, 작으면 안정적인 주식이라고 볼 수 있어.
이제 통계를 보면 “아, 이게 평균 근처에서 얼마나 퍼져 있는지를 나타내는구나!” 하고 쉽게 이해할 수 있을 거야. 😃
'머신러닝' 카테고리의 다른 글
| Cohort 분석 개념 및 사용법 (0) | 2025.03.20 |
|---|---|
| A/B 테스트, 독립변수, 종속변수, 이중차분법 (0) | 2025.03.19 |
| [통계학] 도수분포표 (0) | 2025.03.18 |
| [통계학] 도수, 상대도수, 도수분포표 (0) | 2025.03.18 |
| [통계학 기본] 변량 (0) | 2025.03.18 |